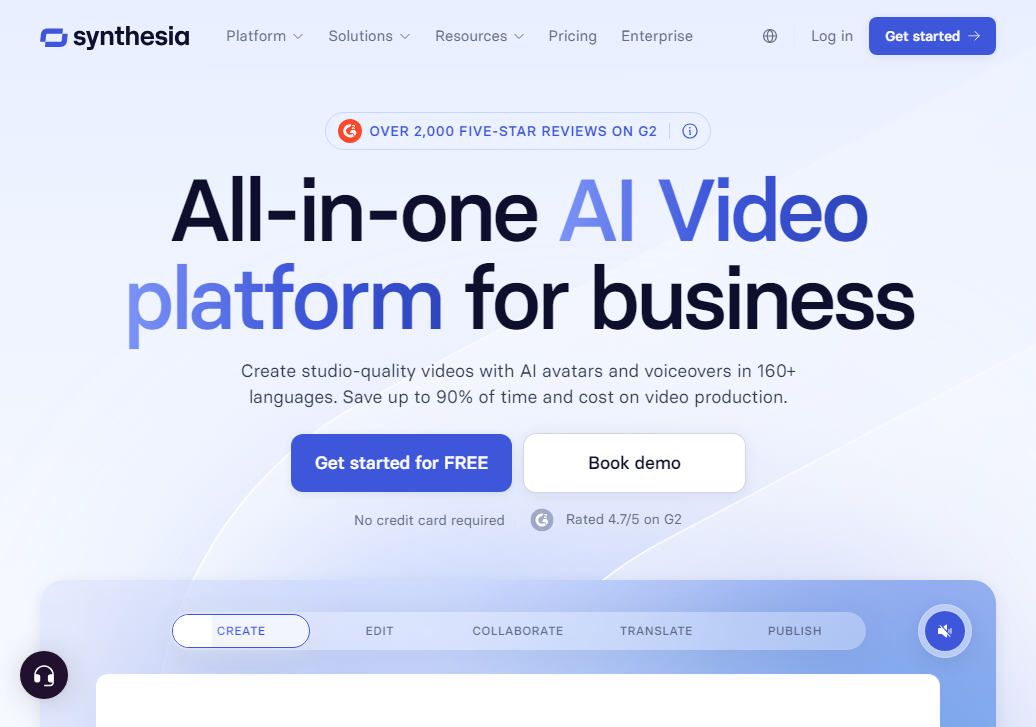
提供超过140种AI虚拟角色,涵盖不同年龄、性别、种族与风格,口型同步精度达毫秒级,面部微表情自然生动。
内置多语种语音引擎,支持包括中文、英语、日语、阿拉伯语在内的120余种语言与地区口音,可精细调节语速、停顿与语调。
可输出1080p全高清视频,支持横屏、竖屏、方形等常见比例;自由添加文本、背景音乐、字幕,适合社交媒体、培训课件等多场景。
Synthesia 于伦敦成立,最初源自伦敦大学学院(UCL)计算机科学系的研究项目,核心团队专注于利用深度学习技术生成逼真的人脸动画与语音同步。
发布首个原型产品,能够通过单张照片驱动数字人脸说出任意文本,并在学术界和早期投资者中引发关注;同年获得来自 LDV Capital 和 Firstminute Capital 的种子轮融资。
推出面向企业用户的 Beta 版平台,允许用户上传脚本并生成带有虚拟主播的演示视频;同年与多家教育科技公司合作,验证了 AI 视频生成在培训场景中的实用性。
Synthesia 正式向公众开放,提供基于浏览器的 AI 视频合成服务;支持超过 40 种语言,并引入“无摄像师”概念——用户无需真人拍摄即可创建专业品质视频。
完成 1250 万美元 A 轮融资,由 Kleiner Perkins 领投;推出自定义虚拟头像功能,企业可创建带有品牌形象的专属 AI 主播;获评 Gartner 2021 年 AI 视频生成领域代表性厂商。
获得 5000 万美元 B 轮融资,估值突破 5 亿美元;发布 AI 视频翻译功能,保留原始说话人的口型与表情的同时实现多语言配音;合作客户包括亚马逊、路透社、IBM 等。
推出 “Expressive AI Avatars”,支持情感化表演(如微笑、皱眉、手势变化);上线视频协作编辑工具,允许多名团队成员在线同步调整脚本、背景与动作;用户量突破 5 万家企业。
完成 C 轮融资,总额达 1 亿美元,估值超过 10 亿美元成为独角兽;发布 Synthesia 2.0,引入实时 AI 化身直播能力与动态背景生成;宣布与微软 Azure 合作,将视频合成功能嵌入企业级工作流。